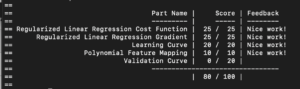
こちらでふりかえりを書いたWebアプリについて、デプロイでうまくいかなかった部分を記録しておく。
概要
ローカルでは一応意図した形で動いてくれていたDjangoをHerokuにデプロイしたところ、エラーが出てうまく動かなかった。そして、そのエラーを解決することができなかった。
自分の理解では、利用しているライブラリが参照しているファイルをうまく参照させることができなかったのでエラーとなったと認識している。
コードはここにいったん置いた。
詳細
1- ログの確認
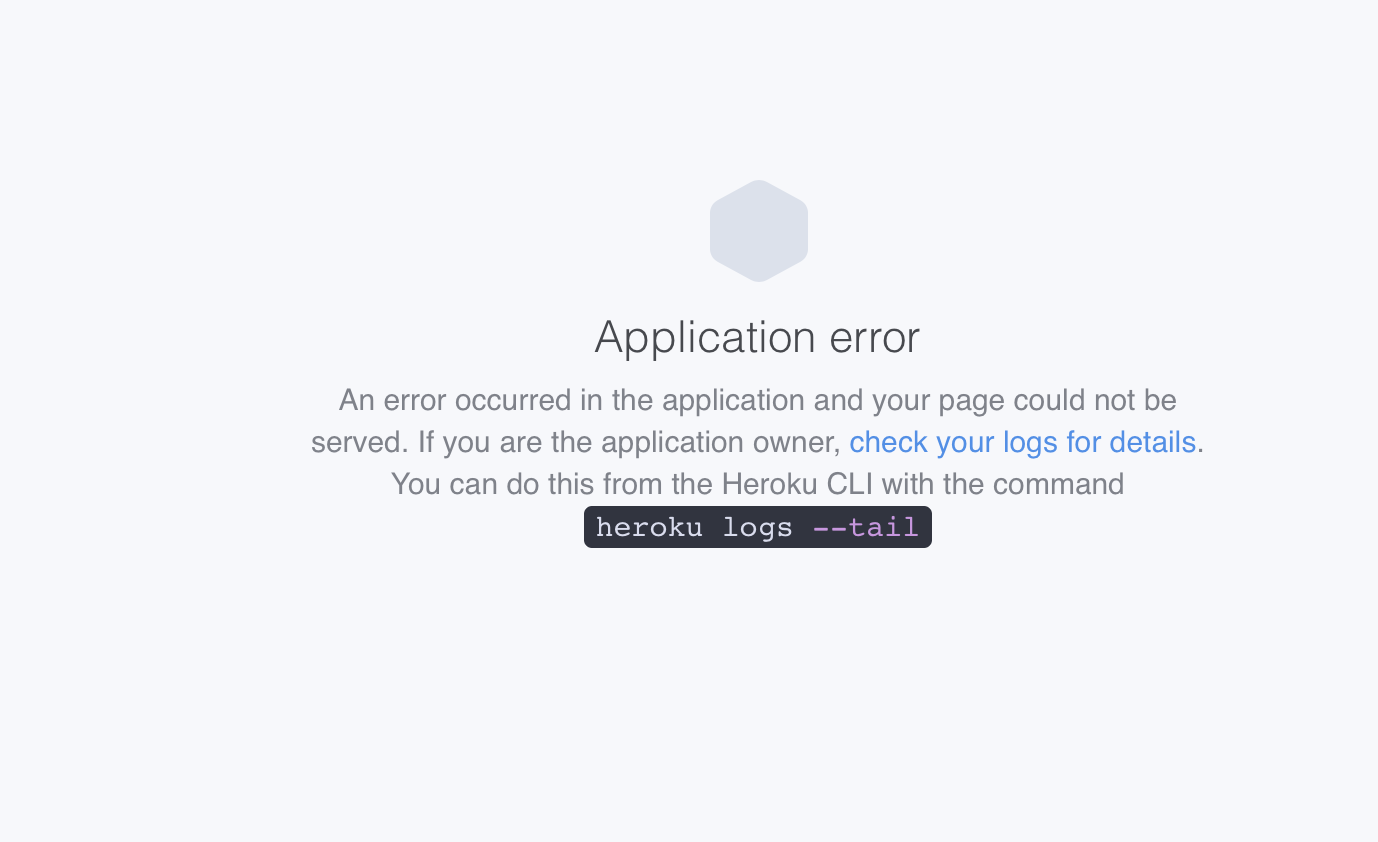
Herokuでデプロイして、該当サイトにアクセスしたところ「Application error」という表示になっていた。
その下に表示されていた文に従い、ログを確認した。
$ heroku logs --tail
(前略)
2019-12-30T05:46:04.064263+00:00 app[web.1]: import osmnx as ox
2019-12-30T05:46:04.064272+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/osmnx/__init__.py", line 9, in
2019-12-30T05:46:04.064274+00:00 app[web.1]: from .core import *
2019-12-30T05:46:04.064276+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/osmnx/core.py", line 10, in
2019-12-30T05:46:04.064278+00:00 app[web.1]: import geopandas as gpd
2019-12-30T05:46:04.064288+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/geopandas/__init__.py", line 1, in
2019-12-30T05:46:04.064290+00:00 app[web.1]: from geopandas.geoseries import GeoSeries # noqa
2019-12-30T05:46:04.064292+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/geopandas/geoseries.py", line 15, in
2019-12-30T05:46:04.064294+00:00 app[web.1]: from geopandas.base import GeoPandasBase, _delegate_property
2019-12-30T05:46:04.064296+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/geopandas/base.py", line 16, in
2019-12-30T05:46:04.064298+00:00 app[web.1]: from rtree.core import RTreeError
2019-12-30T05:46:04.064300+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/rtree/__init__.py", line 1, in
2019-12-30T05:46:04.064302+00:00 app[web.1]: from .index import Rtree
2019-12-30T05:46:04.064310+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/rtree/index.py", line 5, in
2019-12-30T05:46:04.064312+00:00 app[web.1]: from . import core
2019-12-30T05:46:04.064314+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/rtree/core.py", line 125, in
2019-12-30T05:46:04.064316+00:00 app[web.1]: raise OSError("Could not find libspatialindex_c library file")
計算して求めたルートを地図にプロットするのに、osmnxというライブラリを利用している。そして、osmnxではRtreeというライブラリが使用されている。Rtreeのコードの中で、libspatialindex_c library fileが見つからなかったことによりエラーになっていると理解した。
2- ローカルではエラーが起きなかったのは何が違うのか確認する
上記のエラー文にFile "/app/.heroku/python/lib/python3.7/site-packages/rtree/core.py", line 125 とあり、.venv/lib/python3.7/site-packages/rtree/core.pyの125行目付近を確認した。
(/app/.heroku/~というのがどのように確認できるかわからなかったのでvenvでローカルでインストールしたものと同じだろうと考えて上記を確認した)
elif os.name == 'posix':
if 'SPATIALINDEX_C_LIBRARY' in os.environ:
lib_name = os.environ['SPATIALINDEX_C_LIBRARY']
else:
lib_name = find_library('spatialindex_c')
if lib_name is None:
raise OSError("Could not find libspatialindex_c library file")
rt = ctypes.CDLL(lib_name)
else:
raise RTreeError('Unsupported OS "%s"' % os.name)
lib_nameが定義できていなかった(環境変数の中にSPATIALINDEX_C_LIBRARYがなく、またspatialindex_cというライブラリも見つけられなかった)ためにエラーとなっていたことがわかった。
ターミナルでPythonを立ち上げて、ローカル環境だとどうなっているか確認してみた。
>>> import os
>>> os.name
'posix'
>>> os.environ
environ({'TERM_PROGRAM': 'Apple_Terminal',(後略)
>>> from ctypes.util import find_library
>>> find_library('spatialindex_c')
'/usr/local/lib/libspatialindex_c.dylib'
os.environでSPATIALINDEX_C_LIBRARYがなかったことから、ローカル環境ではlib_name = find_library('spatialindex_c')の方が実行されたのだろうこと、またspatialindex_cはローカル環境だと/usr/local/lib/libspatialindex_c.dylibにあるのだということがわかった。
検索してみると、ローカル環境で同じような問題にぶつかっている人がいた。Homebrewでspatialindexをインストールしたら解決したとされており、$ brew listで確認してみるとインストール済みだった。そのため、ローカルでは問題が起きなかったのだろうと思った。
3- どうしたら本番環境でも参照できるようになるか考える
ローカル環境では該当ファイルが存在していたため参照できたが、本番環境には該当のファイルがないためエラーになる。
pipでインストールできるファイルならrequirements.txtに書いておけるけど、そうではなさそうだ。それなら本番環境にもそのファイルを置いて、参照できればとりあえずは解決できるのではと考えた。
/usr/local/lib/libspatialindex_c.dylibをコピーして、本番環境のプロジェクト直下にlibディレクトリを作り、置いてみた。
これが正しい行為なのかわからないけど、環境変数にパスを設定してみた。
$ heroku configで、登録できていることが確認できた。
(前略)
SPATIALINDEX_C_LIBRARY: lib/libspatialindex_c.dylib
この修正をしても同様のエラー画面だったため、再度、$ heroku logs --tailでログを確認した。
(前略)
2019-12-30T06:38:08.950338+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/site-packages/rtree/core.py", line 127, in
2019-12-30T06:38:08.950339+00:00 app[web.1]: rt = ctypes.CDLL(lib_name)
2019-12-30T06:38:08.950340+00:00 app[web.1]: File "/app/.heroku/python/lib/python3.7/ctypes/__init__.py", line 364, in __init__
2019-12-30T06:38:08.950342+00:00 app[web.1]: self._handle = _dlopen(self._name, mode)
2019-12-30T06:38:08.950344+00:00 app[web.1]: OSError: lib/libspatialindex_c.dylib: invalid ELF header
表示が前回と変わっている。
最初のエラーログで出ていたraise OSError("Could not find libspatialindex_c library file")はなく、次の行のrt = ctypes.CDLL(lib_name)が表示されているので、libspatialindex_cを見つけること自体はできたと考えてよいのだろうか。
エラーの最後の行で、invalid ELF headerと表示されている。検索すると、違うOSでのビルドだから読み込めない場合に表示されるという記載があった。
「2- ローカルではエラーが起きなかったのは何が違うのか確認する」に記載した.venv/lib/python3.7/site-packages/rtree/core.pyで、もう少し上の方に以下のような記載箇所がある。
if 'SPATIALINDEX_C_LIBRARY' in os.environ:
lib_path, lib_name = os.path.split(os.environ['SPATIALINDEX_C_LIBRARY'])
rt = _load_library(lib_name, ctypes.cdll.LoadLibrary, (lib_path,))
else:
rt = _load_library('spatialindex_c.dll', ctypes.cdll.LoadLibrary)
if not rt:
raise OSError("could not find or load spatialindex_c.dll")
このspatialindex_c.dllの方が必要なのかなと思い(多分違う)、探したが見つけられなかった。
4- いったん諦める
いったん諦める。もう少し知識がついたらまた考えてみる。












 →
→ 