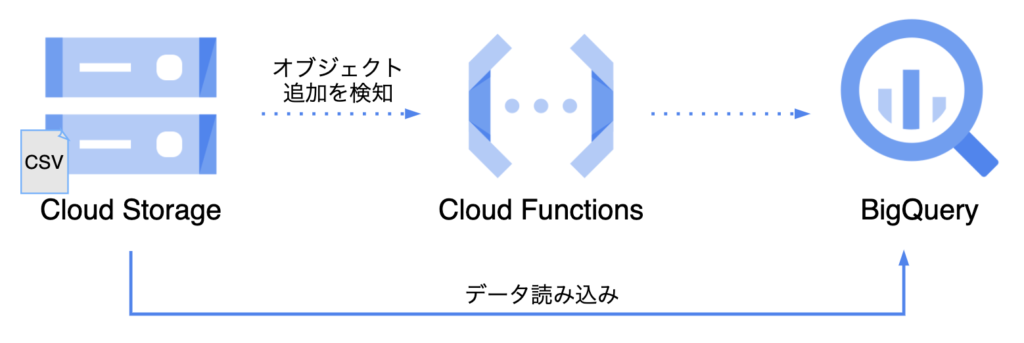
MySQLをインストールして、CSVファイルからテーブルを作るところまでやってみた過程を記録する。
きっかけは、趣味で計測している時間の使い方記録が11,000行を超え、Excelによる取り回しが重くなってきていたこと。CSVのままPythonで操作するのでもよかったけど、せっかくなのでデータベース化をやってみた。
バージョン
- macOS 10.13.6
- MySQL 8.0.15
具体的な操作
以下、リンク先は公式ドキュメントの参照したページ
1 – MySQLのインストール
まず、homebrewでMySQLをインストールした。
$ brew install mysql
(前略)
==> Caveats
We've installed your MySQL database without a root password. To secure it run:
mysql_secure_installation
MySQL is configured to only allow connections from localhost by default
To connect run:
mysql -uroot
To have launchd start mysql now and restart at login:
brew services start mysql
Or, if you don't want/need a background service you can just run:
mysql.server start
(後略)
一番目に書かれている$ mysql_secure_installationをやろうとする。
$ mysql_secure_installation
Securing the MySQL server deployment.
Enter password for user root:
Error: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
パスワードの設定をしていなかったので、Enter password for user root:でそのままEnterを押したが、エラーになった。
can-not-connect-to-serverに
A MySQL client on Unix can connect to the mysqld server in two different ways: By using a Unix socket file to connect through a file in the file system (default /tmp/mysql.sock), or by using TCP/IP, which connects through a port number.
とあり、接続方法の一つであるソケット接続に失敗したようだ。
結局、MySQLの起動($ mysql.server start)が必要だったようで、その後なら$ mysql_secure_installationを行えた。
$ mysql.server start
Starting MySQL
........ SUCCESS!
$ mysql_secure_installation
Securing the MySQL server deployment.
(長いので後略)
これにより、どのようにセキュリティが向上するかがmysql-secure-installation に書かれている。
- anonymousユーザー(匿名ユーザー)の削除
- リモートホストからroot ユーザー(MySQLの操作に対し全権限を持つユーザー)でのログイン禁止
- testデータベースの削除
などを行った。
2 – MySQLに接続する
$ mysql -u user -pという形で接続する。-uでユーザー名を指定し、-pとすると Enter password: というプロンプトが表示されるのでパスワードを入力する。
rootユーザーでつないでみる。
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 8.0.15 Homebrew
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
つながった!
どんなデータベースがあるか見てみる(testデータベースが消えていることが確認できる)。
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.06 sec)
3 – データベースを作る
lifeというデータベースを作り、その中にtime_bookというテーブルを作成する。
データベースを作る
mysql> CREATE DATABASE life;
Query OK, 1 row affected (0.08 sec)
テーブルを作る
mysql> CREATE TABLE life.time_book(
-> id INTEGER PRIMARY KEY AUTO_INCREMENT,
-> start_datetime DATETIME NOT NULL,
-> end_datetime DATETIME NOT NULL,
-> duration TIME NOT NULL,
-> content VARCHAR(24) NOT NULL,
-> memo VARCHAR(60)
-> );
Query OK, 0 rows affected (0.69 sec)
CREATE TABLE db_name.table_name(col_name data_type, …);という形で作れる。
- data_typeはデータ型 今回使用しているのはDATETIME(日付と時刻),TIME(時刻),VARCHAR(可変長文字列)
- NOT NULL:そのカラムにはNULLを格納することができなくなる
- PRIMARY KEY:主キー制約 行の一意性を確保する
- AUTO_INCREMENT:連番を自動的に振る
テーブル一覧を確認する
mysql> SHOW TABLES FROM life;
+----------------+
| Tables_in_life |
+----------------+
| time_book |
+----------------+
1 row in set (0.09 sec)
テーブルのカラム一覧を確認する
mysql> SHOW COLUMNS FROM time_book FROM life;
+----------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| start_datetime | datetime | NO | | NULL | |
| end_datetime | datetime | NO | | NULL | |
| duration | time | NO | | NULL | |
| content | varchar(24) | NO | | NULL | |
| memo | varchar(60) | YES | | NULL | |
+----------------+-------------+------+-----+---------+----------------+
6 rows in set (0.06 sec)
4 – CSVファイルからデータを挿入する
まずデータベースを選択する。
mysql> use life;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
CSVを準備する
~/time_book.csv
id,start_datetime,end_datetime,duration,content,memo
1,2017-01-02 09:45,2017-01-02 10:34,00:49,'移動',
2,2017-01-02 10:34,2017-01-02 11:34,01:00,'家事','料理'
…
データをローカルから読み込もうとする。
mysql> LOAD DATA LOCAL INFILE '~/time_book.csv'
-> INTO TABLE time_book
-> FIELDS TERMINATED BY ','
-> IGNORE 1 LINES;
ERROR 1148 (42000): The used command is not allowed with this MySQL version
FIELDS TERMINATED BY ','はカンマ区切りを指定しているIGNORE 1 LINESはCSVの1行目がカラム名なので、読み込まないようにするため
エラーになった。
load-data-localを参照すると
- セキュリティの問題から、デフォルトではLOAD DATA LOCALを使えないようにしてある
- サーバー側、クライアント側それぞれで許可の設定が必要
なことがわかった。
サーバーサイド
The local_infile system variable controls server-side LOCAL capability. Depending on the local_infile setting, the server refuses or permits local data loading by clients that have LOCAL enabled on the client side. By default, local_infile is disabled.
option-modifiersで
The “enabled” form of the option may be specified in any of these ways:
(中略)
–column-names=1
とあるので、1にすれば有効になる。
mysql> SET PERSIST local_infile = 1;
Query OK, 0 rows affected (0.08 sec)
SET文でシステム変数を変更できる(再起動すると設定した内容が失われる)。 SET PERSISTでパラメーターの値を設定すると、再起動後も値が保持される。
mysql> SELECT @@local_infile;
+----------------+
| @@local_infile |
+----------------+
| 1 |
+----------------+
1 row in set (0.00 sec)
クライアントサイド
For the mysql client, local data loading is disabled by default. To disable or enable it explicitly, use the –local-infile=0 or –local-infile[=1] option.
接続時に–local-infile=1と指定する
$ mysql -u root --local-infile=1 -p
サーバー側、クライアント側それぞれで設定できたので、改めてLOAD DATA LOCAL INFILEしたところ、先ほどのエラーは出なくなったが、以下の結果になった。
Query OK, 0 rows affected (0.10 sec)
Records: 0 Deleted: 0 Skipped: 0 Warnings: 0
OKって出てるけど、Records: 0ということはつまり…中身を確認する。
mysql> select * from time_book;
Empty set (0.04 sec)
やっぱり読み込まれていない。
試行錯誤しながら問題がある部分を修正していったので、以下1つずつ示す。
- datetimeとtimeの型の部分を””で囲っていなかった
最初はLOAD DATA LOCAL INFILEでやっているのが原因かと思い、試しにinsert文で読み込めるかやっていた中で気づいた。
mysql> insert into time_book (start_datetime,end_datetime,duration,content,memo) values(1990-01-01 00:00, 1990-01-01 00:01, 00:01:00, "a","b");
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '00:00, 1990-01-01 00:01, 00:01:00, "a","b")' at line 1
mysql> insert into time_book (start_datetime,end_datetime,duration,content,memo) values("1990-01-01 00:00", "1990-01-01 00:01", "00:01:00", "a","b");
Query OK, 1 row affected (0.03 sec)
“”で日時を囲ったら読み込めた。ごく基本的な話なんだけど、わかっていなかった。
CSVファイルを修正し、LOAD DATA LOCAL INFILEにFIELDS ENCLOSED BY "'"を追加した(これは要素を囲むのに’ ‘を使っていることを指定している)。
まず、MySQL側での文字コードを確認する。
mysql> SHOW VARIABLES LIKE 'char%';
+--------------------------+------------------------------------------------------+
| Variable_name | Value |
+--------------------------+------------------------------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/Cellar/mysql/8.0.15/share/mysql/charsets/ |
+--------------------------+------------------------------------------------------+
8 rows in set (0.00 sec)
utf8mb4って何…?と思い内容を見てみる。
mysql> SHOW CHARACTER SET LIKE "utf8%";
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+---------+---------------+--------------------+--------+
2 rows in set (0.00 sec)
utf8mb4もUTF-8の一種っぽい。
csvファイルの文字コードを確認する
$ file --mime time_book.csv
time_book.csv: text/plain; charset=unknown-8bit
UTF-8でなかったので、$ iconvで文字コードを変えようとする。
$ iconv -f unknown-8bit -t utf8 time_book.csv > time_book.csv
iconv: conversion from unknown-8bit unsupported
iconv: try 'iconv -l' to get the list of supported encodings
unknown-8bitという文字コードは対応していないと言われる。$ iconv -lで見てみると、確かにunknown-8bitというのはない。$ iconvでは出来ないのか…と思ったが、unknown-8bitはshift_JISのことのようだとわかった。
$ iconv -f shift_JIS -t utf8 time_book.csv > time_book.csv
$ file --mime time_book.csv
time_book.csv: text/plain; charset=utf-8
CSVファイルをUTF-8に変換できた。
上記を修正しても、LOAD DATA LOCAL INFILEで1行目しか読み込まれなかったことから気づいた。
LOAD DATA LOCAL INFILEにLINES TERMINATED BY '\r'を追加した。
- (これは、読み込みができなかったのと直接関係しないが)id列について、auto_incrementなのに数字を入れていた
mysql> SHOW COLUMNS FROM time_book FROM life;で見ると、id列のNullがnoになっていたので、auto_incrementだけど数値を入れていた。
example-auto-incrementで
No value was specified for the AUTO_INCREMENT column, so MySQL assigned sequence numbers automatically. You can also explicitly assign 0 to the column to generate sequence numbers, unless the NO_AUTO_VALUE_ON_ZERO SQL mode is enabled.
とあったので、id列は0に変更した。
結果、CSVはこのような形になった。
id,start_datetime,end_datetime,duration,content,memo
0,'2017-01-02 09:45','2017-01-02 10:34','00:49','移動',
0,'2017-01-02 10:34','2017-01-02 11:34','01:00','家事','料理'
再度csvを読み込み
mysql> LOAD DATA LOCAL INFILE '~/time_book.csv'
-> INTO TABLE time_book
-> FIELDS TERMINATED BY ',' ENCLOSED BY "'"
-> LINES TERMINATED BY '\r'
-> IGNORE 1 LINES;
Query OK, 11348 rows affected, 1 warning (0.59 sec)
Records: 11348 Deleted: 0 Skipped: 0 Warnings: 1
読み込みができたっぽいぞ!
mysql> SELECT * FROM life.time_book LIMIT 2;
+----+---------------------+---------------------+----------+---------+--------------+
| id | start_datetime | end_datetime | duration | content | memo |
+----+---------------------+---------------------+----------+---------+--------------+
| 1 | 2017-01-02 09:45:00 | 2017-01-02 10:34:00 | 00:49:00 | 移動 | |
| 2 | 2017-01-02 10:34:00 | 2017-01-02 11:34:00 | 01:00:00 | 家事 | 料理 |
+----+---------------------+---------------------+----------+---------+--------------+
2 rows in set (0.00 sec)
できた!
感想
なるべく公式ドキュメント(英語)のみで理解しようとして進めたけど、けっこうつらかった。今回よりも古いバージョンなら日本語のドキュメントもあって、わからない場合はそちらも参照したけど、英語で読んでわからない場合は日本語でもだいたいわからず、英語力でなく知識不足が原因か、と思いつつ不明な単語等を調べて進めていった。
単に1つのテーブルを作るだけなのに各所で色々引っかかったけど、作業自体は全般的に楽しかった。やっとデータが読み込めた時はうれしくて、ひとり小躍りした。