
前の記事では、手動でBigQueryにデータを読み込む方法を試した。この記事では、データが新しく生成されたら自動で読み込みを行いたいケースを想定し、「Cloud StorageにCSVファイルが追加されたら、自動でBigQueryにデータを読み込む」ことを目標に進める。
概要
今回はCloud Functionsを使った。Cloud FunctionsはGCP上で関数を実行できるサービスで、関数を実行するトリガーの一つにCloud Storageでのイベントの発生がある。そのため、今回の「Cloud StorageにCSVファイルが追加されたら」もトリガーとして設定できる。
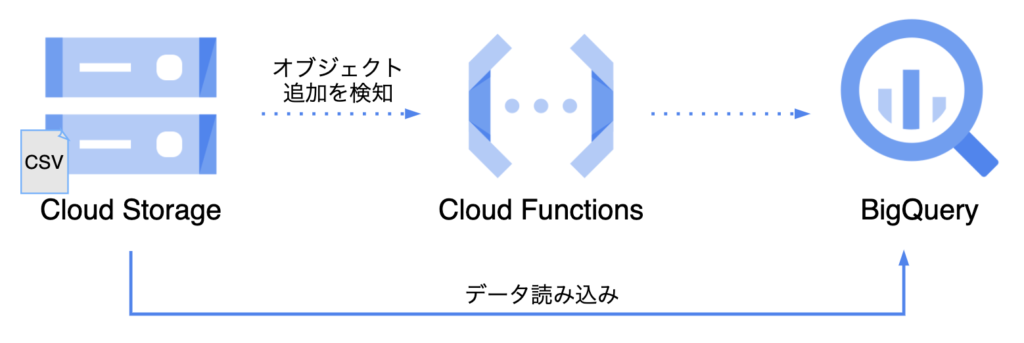
今回、やりたいことを分解すると以下の2つが必要になる。
A. Cloud Storageにオブジェクトが追加されたことをトリガーとしてCloud Fuctionsの関数を実行する B. Cloud Fuctionsの関数内で、BigQueryのデータにアクセスして操作を行う
今回、まずはA, Bそれぞれ単体で試して作り方を確認後、AとBを合わせて元々作りたかった関数を作成する手順で進めた。不慣れでA, B単体でもエラーが出たり色々とまどう部分があったので、それも含めて記載していく。
A. Cloud Storageにオブジェクトが追加されたことをトリガーとしてCloud Fuctionsの関数を実行する
B. Cloud Fuctionsの関数において、BigQueryのデータにアクセスして操作を行う
C. Cloud Storageにオブジェクトが追加されたらBigQueryにデータを読み込む
手順
A. Cloud Storageにオブジェクトが追加されたことをトリガーとしてCloud Fuctionsの関数を実行する
Cloud Storage のチュートリアル | Cloud Functions ドキュメントに、Cloud Storageでは下記4点のイベントに対応していると記載がある。
・ ファイナライズ
・ 削除
・ アーカイブ
・ メタデータの更新
このうち、ファイナライズについて
オブジェクト ファイナライズ イベントは、Cloud Storage オブジェクトの「書き込み」が正常にファイナライズされた時点でトリガーされます。つまり、新しいオブジェクトの作成または既存のオブジェクトの上書きによって、このイベントがトリガーされます。
とあるので、今回はファイナライズをトリガーとすればよいことがわかった。
同ドキュメント内でファイナライズのサンプル関数が掲載されているので、それを以下で実行してみた(ただし、ドキュメントはコマンドラインを用いた操作手順だったが、今回はCloud Consoleから操作した)。
① 関数を作成する(トリガーの指定)
1) 関数の作成をクリック
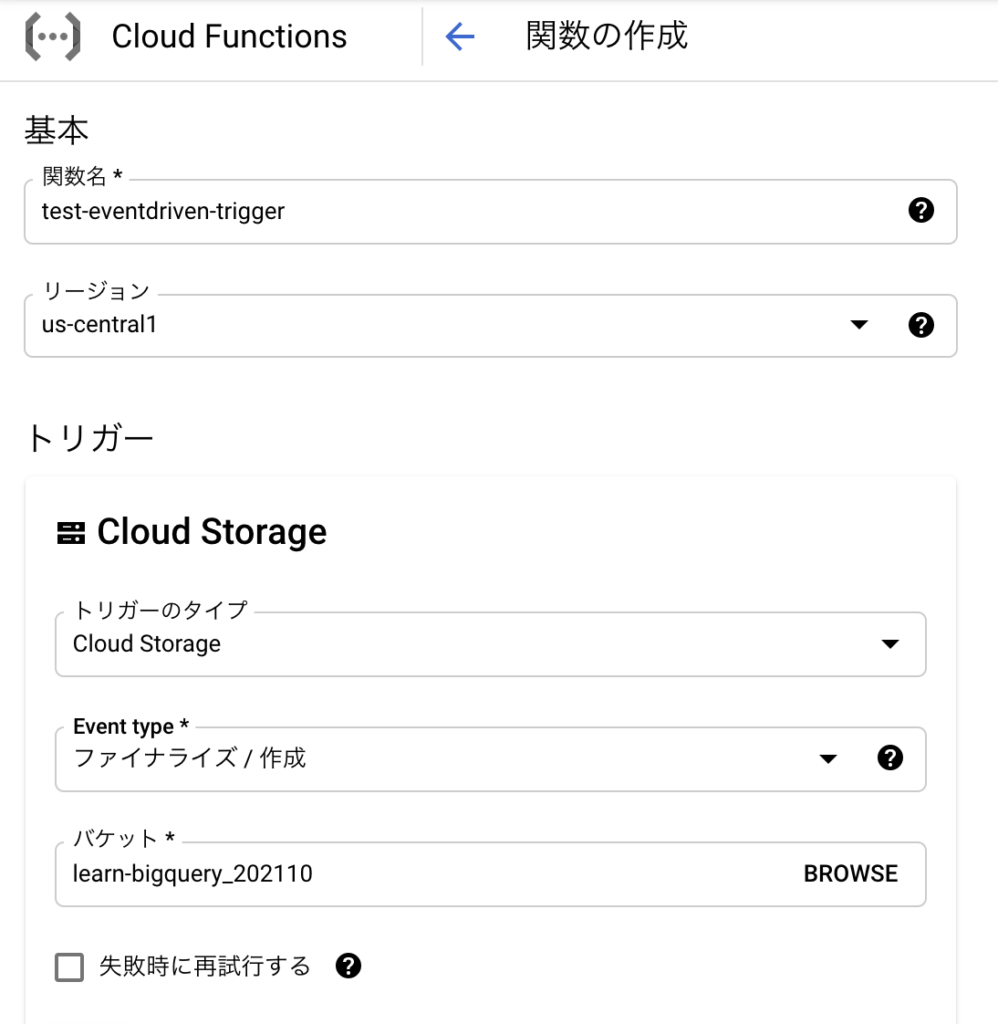
2) 関数名、リージョン、トリガーの内容等を入力
トリガーのEvent typeは先ほど記載したファイナライズ、バケットはCloud Fucntionsのオブジェクトのアップロード先バケットを指定する。
② 関数を作成する(関数の内容の記載)
チュートリアルに記載の内容のままmain.pyに記載する。

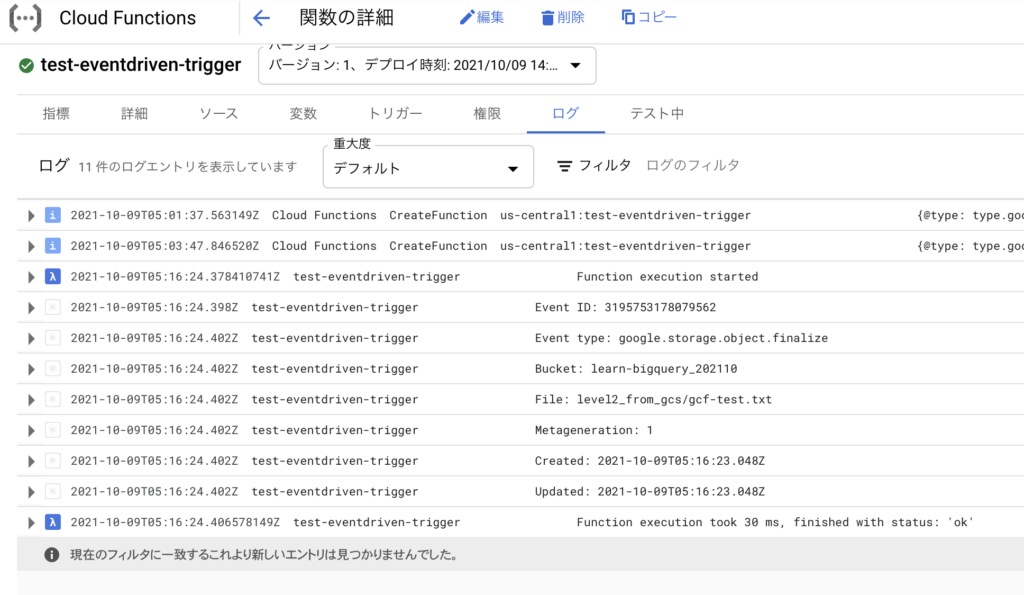
③ 関数が動作することを確認する
先ほど指定したCloud Storageのバケットに適当にテキストファイルをアップロードし、これをトリガーとして関数が実行されることを確認する。Cloud Functionsのログに、print関数の結果が吐き出されていることを確認した。
B. Cloud Fuctionsの関数において、BigQueryのデータにアクセスして操作を行う
クイックスタート: クライアント ライブラリの使用 | BigQuery ドキュメントにBigQueryのテーブルにクエリを投げてデータを取得する関数の事例が掲載されている。今回最終的に行いたいのはSelect クエリではなくデータのインサートだが、まずはこの事例を試してみる。
① クエリを実行する関数を作成する
A.と同様の手順で、記載の関数を少し変形してCloud Functionsにデプロイした。(※ このB.では、トリガーはHTTPリクエストとなっている)
main.py
from google.cloud import bigquery
def query_stackoverflow(request):
client = bigquery.Client()
query_job = client.query(
"""
SELECT
CONCAT(
'https://stackoverflow.com/questions/',
CAST(id as STRING)) as url,
view_count
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE tags like '%google-bigquery%'
ORDER BY view_count DESC
LIMIT 10
"""
)
results = query_job.result() # Waits for job to complete.
for row in results:
print("{} : {} views".format(row.url, row.view_count))
return "finish!"requirements.txt
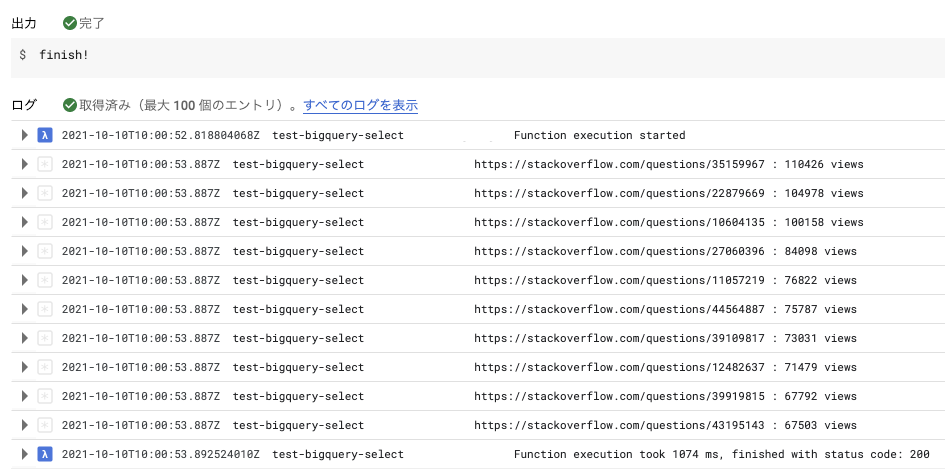
google-cloud-bigquery>=1.28.0② 関数をテストする
200が返ってきてprint関数が出力されていることが確認できる。
つまずいた点
上記手順で実行できるまでにつまずいた点を記載する。
1) requirements.txtの不足
requirements.txtを記載していなかったところ、以下のようなエラーが出た。
"/workspace/main.py", line 1, infrom google.cloud import bigquery ImportError: cannot import name 'bigquery' from 'google.cloud' (unknown location)
今回ローカルに開発環境を作らずCloud Consoleで行っていたので、予めインストールされるようなイメージを勝手に持ってしまっていたけど、requirements.txtへの記載が必要だった。
requirements.txtに google-cloud-bigquery>=1.28.0 を記載することで解決した。
2) 引数の不足
上記手順で def query_stackoverflow(request): としているところを当初 def query_stackoverflow(): として引数を入れていなかったらエラーとなった。ログには以下の記載があった。
TypeError: query_stackoverflow() takes 0 positional arguments but 1 was given
関数の内容上、引数は必要なかったため記載していなかったが、Cloud Functionsでトリガーにより実行する場合は暗黙的に引数が渡されるため関数で引数が必要なようだった(参考)(ドキュメントでの明確な言及は見つけられなかったが、トリガーにより実行する以上、引数が必要なのは当然ということなのかもしれない)。
関数の引数を追加することで解決した。
3) returnの不足
特に何も返さない関数にしていたところ、以下のエラーが返ってきた。
TypeError( TypeError: The view function did not return a valid response. The function either returned None or ended without a return statement.
関数の内容上、特に必要なかったが関数にreturnを追加することで解決した。
C. Cloud Storageにオブジェクトが追加されたらBigQueryにデータを読み込む
A, Bを試す中で今回やりたいことに必要な概要がつかめたので、最終的にやりたかった内容の関数を作る。
B.ではSelectクエリの実行だったけど、この部分をCSVデータの読み込みに置き換える必要がある。この部分はCloud Storage からの CSV データの読み込み | BigQuery ドキュメントを参照した。
① 関数をデプロイする
関数のデプロイ手順自体はA.と同様。
任意の名称のCSVファイルが追加されたら、BigQueryにデータの追加を行うようにした。
main.py
from google.cloud import bigquery
def append_data_into_bigquery(table_id, uri):
client = bigquery.Client()
job_config = bigquery.LoadJobConfig(
autodetect=True, # スキーマの自動検出
write_disposition=bigquery.WriteDisposition.WRITE_APPEND, # データの追加
skip_leading_rows=1 # 冒頭1行は今回ヘッダ行なので読み飛ばし
)
load_job = client.load_table_from_uri(
uri,
table_id,
job_config=job_config
)
load_job.result()
table = client.get_table(table_id)
print("Loaded {} rows to table {}".format(table.num_rows, table_id))
def append_weather_data_into_bigquery(event, context):
if event['name'].endswith('weather_tokyo.csv') == True:
project_id = 'learn-bigquery-327203'
bq_dataset = 'level2_from_gcs'
bq_table = 'weather_tokyo'
table_id = project_id + '.' + bq_dataset + '.' + bq_table # project.dataset.table_name
uri = 'gs://' + event['bucket'] + '/' + event['name'] # gs://bucket_name/object_name_or_glob
append_data_into_bigquery(table_id, uri)requirements.txt
google-cloud-bigquery>=1.28.0
② 関数が実行されることを確認する
Cloud StorageにCSVファイルをアップロードしたことをトリガーとして、BigQueryにデータがインサートされるかを確認する。
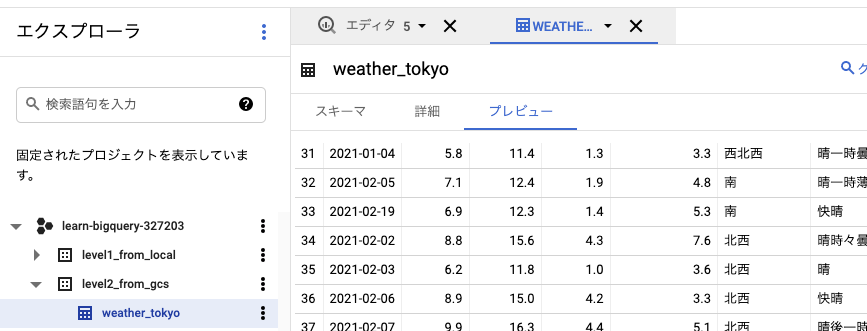
Cloud Functionsのログでは関数の実行が完了した旨が出ている。

BigQueryでも、データが追加されていることが確認できた。
次:
今回、Cloud StorageにCSVデータが追加されたら自動でBigQueryにデータを読み込むことをやってみた。しかしながら、CSVは予め手動でBigQueryに受け入れられる形式に変換していた。この部分も自動化できそうなので、次回はその辺りもGCP上で行う方法を調べてみたい。
