
前の記事では、Cloud Functionsを使い、Cloud StorageにCSVファイルが追加されたらBigQueryに自動で読み込むことをしてみた。この際、CSVは予め手動で整形した上でCloud Storageに置いていた。
この記事では、CSVをBigQueryに読み込み可能な状態に整形する過程を自動化する方法を探る。
概要
今回、Cloud Data Fusionを用いてCSV整形を実施してみた。
Cloud Data Fusionは、データパイプラインをGUIで作成できるサービスで、ETLのTransform部分も様々な機能が用意されているため、CSVの整形もGUIで行えてしまう。
今回は、以下の2段階で進めた手順をまとめた。
A. 定型的にCSVを整形し、BigQueryに読み込む手順をCloud Data Fusionで作成する
B. 任意のCSVファイル名を渡したらA.が実行されるようにする
事前準備
クイックスタート|Cloud Data Fusion ドキュメント を参照して、APIを有効にし、インスタンスを作成しておく。
下記のように、インスタンス名の前に緑のチェックマークが入ったら作成完了。
操作方法や概観をつかむため、事前に以下のチュートリアルをやった。
- ターゲティングキャンペーンパイプライン | Cloud Data Fusion ドキュメント
顧客一覧から、住所が特定の条件に合致する顧客情報のみを抜き出すという内容。今回の目的のうち、CSVの整形を行う部分で参考になった。
- 再利用可能なパイプラインの作成 | Cloud Data Fusion ドキュメント
引数で情報を渡すよう設定し、再利用可能なパイプラインを構築するという内容。今回の目的のうち、CSVのファイル名を与えたら実行されるよう設定しておく部分で参考になった。
手順
A. 定型的にCSVを整形し、BigQueryに読み込む手順をCloud Data Fusionで作成する
スタートとゴール
前の記事同様、気象庁のデータを使用する。
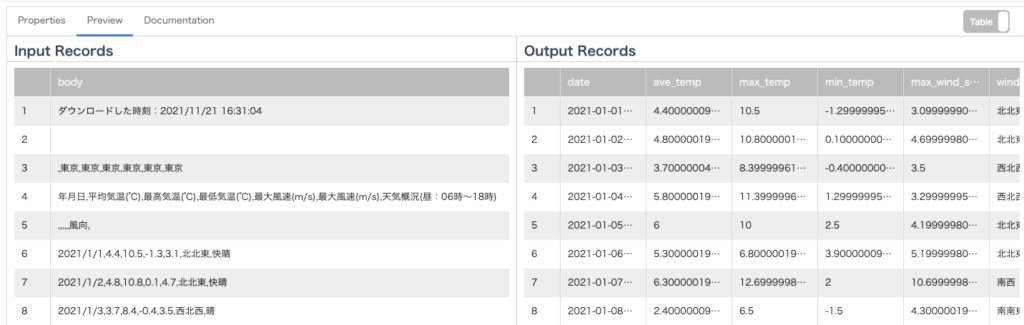
気象庁のHPからダウンロードした段階では、以下のような形式になっている。このCSVをCloud Storageの特定のフォルダに置いた状態からスタートする。
ダウンロードした時刻:2021/11/21 16:31:04
,東京,東京,東京,東京,東京,東京
年月日,平均気温(℃),最高気温(℃),最低気温(℃),最大風速(m/s),最大風速(m/s),天気概況(昼:06時~18時)
,,,,,風向,
2021/1/1,4.4,10.5,-1.3,3.1,北北東,快晴
2021/1/2,4.8,10.8,0.1,4.7,北北東,快晴これを下記の形式にData Fusion内で整形し、BigQueryに格納することを目指す。
date,ave_temp,max_temp,min_temp,max_wind_speed,wind_direction,weather
2021-01-01,4.4,10.5,-1.3,3.1,北北東,快晴
2021-01-02,4.8,10.8,0.1,4.7,北北東,快晴① 読み込み先のBigQueryの準備をしておく
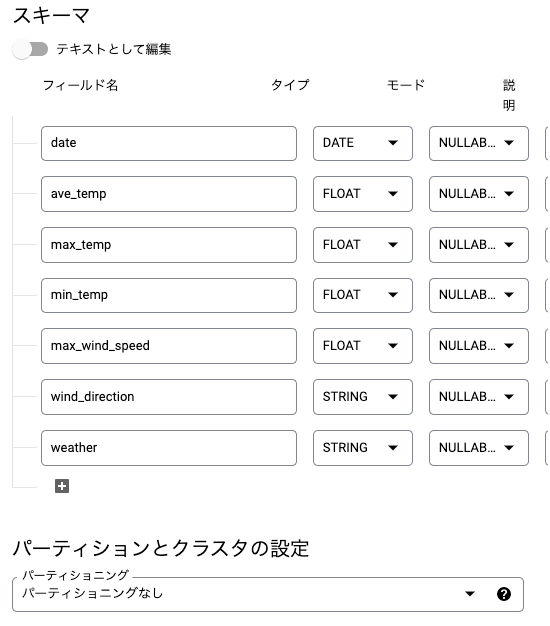
BigQueryに読み込み先のデータセットとテーブルを準備しておく。
スキーマはこれからCloud Data Fusionで整形する予定の内容に合わせておく。
② Cloud Data Fusion UIでCSVを読み込む
「事前準備」でインスタンスを作成してあるので、アクションの「インスタンスを表示」をクリックすると、UIに画面が遷移する。
Wrangleをクリックする。
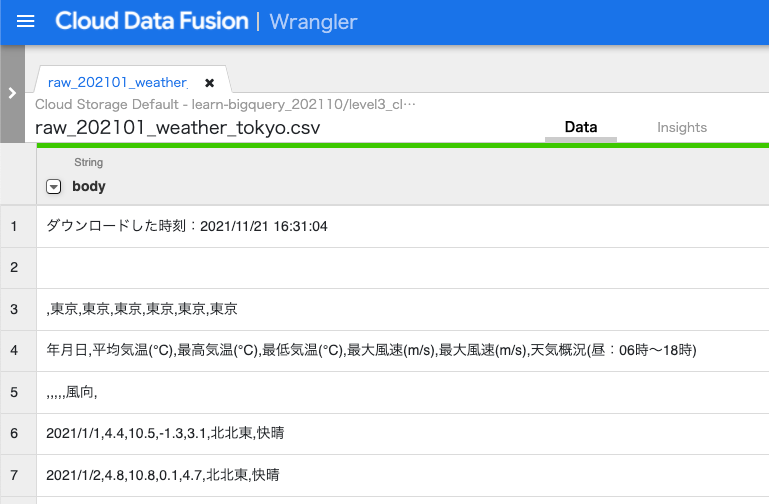
Upload元としてCloud Storageを選択し、用意しておいたCSVを読み込むと、以下のような感じで表示される。行によってカンマの数が異なるデータのため、うまくカンマ区切りで読み込まれず、全て1列に入る形になっている。
③ データを整形する
ゴールの内容に合うようにデータを整形していく。
- 不要なヘッダーの削除
今回は冒頭の5行を消してしまい、列名は後から付け直す方針で進める。Filter > value matches regexで正規表現により日付から始まる列のみ残すように(冒頭の5行を削除するように)した。
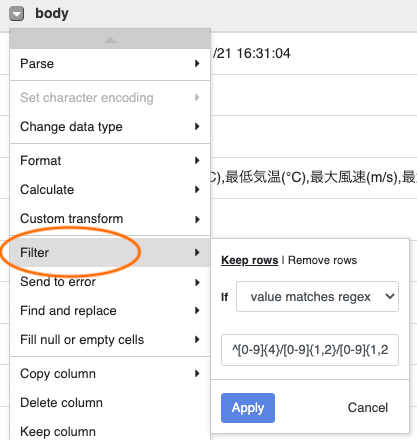
- カンマ区切りで区切る
Parse > CSVを選択し、区切り文字はCommaを選択する。
ここまでの処理でこのような形式になっている。
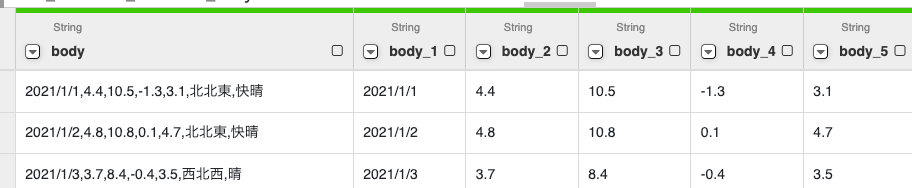
- 不要な列を削除する
カラム区切りで分割した際、分割前の状態も列として残っていている。不要なためDelete columnより削除する。
- 列名をつける
各列打ち替えていく。

- 型変換
- 日付:読み込んだ時点では1行全体で1つの文字列として判断されているため、現状日付も文字列となっている。
Parse > Simple dateより、今回2021/1/1形式だったのでCustom formatを選択し、yyyy/m/dで実行した。
- 日付:読み込んだ時点では1行全体で1つの文字列として判断されているため、現状日付も文字列となっている。
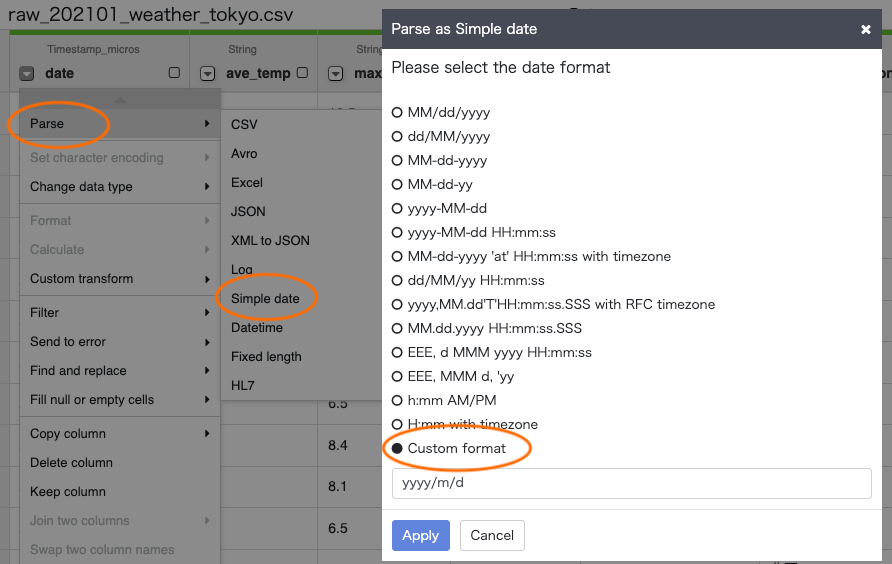
すると、不要な時間までついてきてしまった。
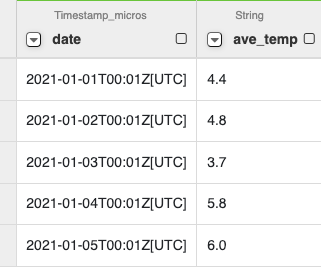
公式のドキュメントでは見つけられなかったのだけど、stack overflowを参照して、Custom transform > date.toLocalDate()をかけたら、Date型になってくれた。
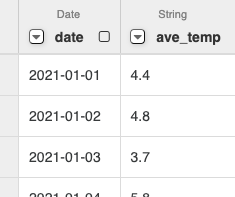
- 数値:
Change data type > Floatを選択して変換する。
Wranglerで行った各変換は画面右で表示されており、不要な処理を削除することが可能。
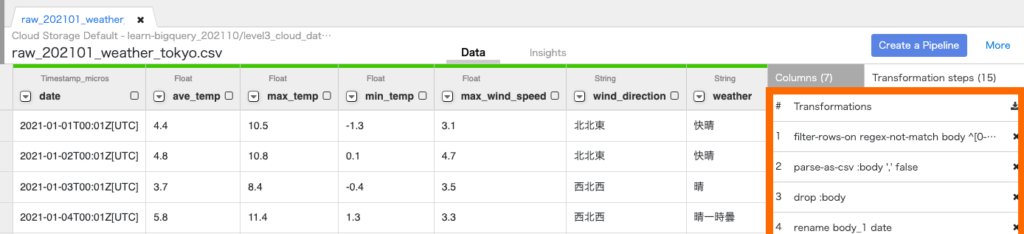
④パイプライン作成
Create a Pipeline をクリックし、Batch pipelineを選択すると
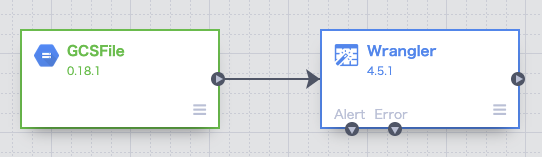
データ元のGCSと設定したWranglerがパイプラインでつながった状態で表示される。
⑤ データの書き出し先を設定する(BigQuery)
Sink > BigQueryを選択(Sinkはデータの出力先)してBigQueryのノードを追加し、Wranglerと接続する。
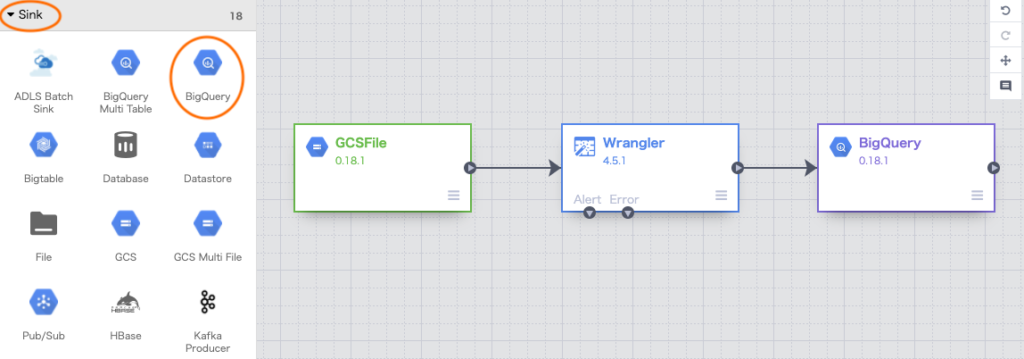
ポインタをBigQuryノードの上に置くとPropertiesが表示されるので、クリックする。BigQuery側のデータセットやテーブル等の指定を行う。
⑥ デプロイと実行
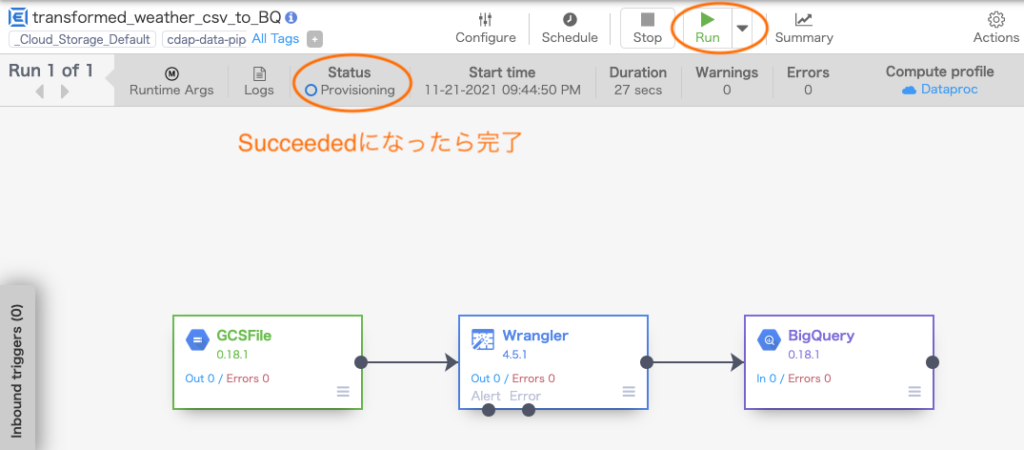
Runをクリックすると、処理が進んでいく(けっこう時間がかかった 20分程度)。Statusの部分の表示で処理の段階がわかり、無事成功すると最終的にSucceededになる。
B. 任意のCSVファイル名を渡したらA.が実行されるようにする
A. では、元となるCSVファイル名をベタ打ちで指定していた。これだとファイル名が変わるたびに毎回作り直す必要があるので、任意のファイル名を渡して処理を実行できるようにしたい。
A. の処理をベースにし、一部書き換える。
① データの読み込み先の変更
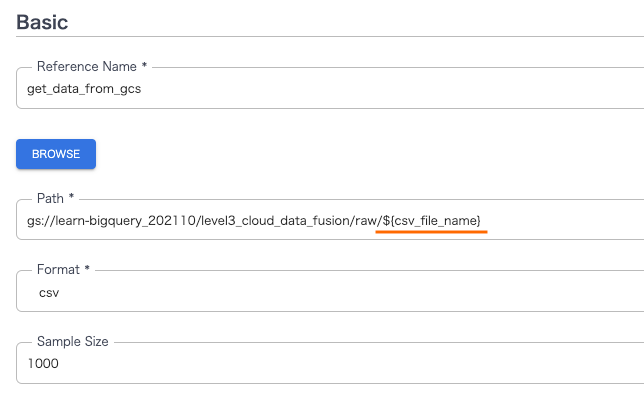
Cloud Storageからの読み込んでいる最初のノードのPropertiesをクリックし、読み込み先のパスの指定部分末尾のCSVファイル名が入る部分を${csv_file_name}に変更する。
※ 下図のFormat部分をcsvとしているが、ここは今回textにする必要があった(csvだと1行目しか読み込まれなかった。おそらく、今回のCSVファイルがCSVと判断される形式でなかったのが要因)
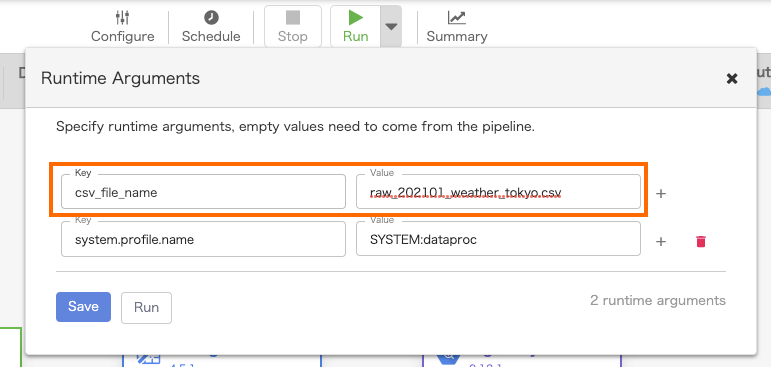
② デプロイ
変数を入れてRunしてみると、無事成功した。
未解決な部分
今回文字列として読み込まれた小数点の数値列について、文字列からFloatに変換すると元々存在しなかった不要な桁が出てしまったが、これをうまく処理することができなかった。
round関数があるので、wranglerでround(ave_temp, 1)などと試してみたが、エラーになり、roundの桁数を指定する方法が見つけられなかった。
この記事の中で、
We could write the recipe for the transformation directly with Directives using JEXL syntax(https://commons.apache.org/proper/commons-jexl/reference/syntax.html)
とあったので、該当ページを参照したが、今回行いたい操作のヒントは得ることができなかった。
まとめ
今回、Data Fusionを利用してCSVファイルの整形を行ってみた。GUIで様々な処理が行えるのはとっつきやすくはあったが、少し込み入った処理をしようとするとやりづらかったり、結局学習コストがかかるので、コードを書いて管理する方が楽かもしれないと感じた。
次は、ワークフローを管理できるCloud Composerを触ってみたい。
