

以前作成したレシート画像から品目や価格を読み取りCSV化する仕組みについて、品目の判定精度が低く困っていた。そこで、読み取った品目と過去履歴の品目との類似度を求める仕組みを組み込むことで、品目判定の精度が上がったのでやったことを記録する。
困りごと
元々の仕組みでは、下記のようにOCRによる品目の読み取り結果とそれを人が見て修正した結果をペアで履歴としてたまるようにしておき、全く同じ読み取り結果を得た時にのみ人が修正した結果に自動で変換するようにしていた。
# 読み取り結果,人が修正した結果 キャベッ,キャベツ TV1.0テイシボ,牛乳 Pロコリー,ブロッコリー # 次回以降に「Pロコリー」という読み取り結果が得られた時に「ブロッコリー」に自動変換する
普段買うものはある程度決まっているため、履歴がたまってくれば人手による修正は減っていくだろうと思っていた。実際は読み取り結果が予想よりバラエティに富んでいて(読み取り精度が思ったより低くて)、人手による修正はなかなか減らなかった。
例えば、以下はレシートに「ブルガリアYG脂肪0プ」と印字されていた場合の読み取り結果の履歴一覧である(印字は「ブルガリアヨーグルト脂肪0プレーン」の略称と思われる)。間違い探しのように毎回少しずつ異なる結果が得られて、なかなか自動修正されなかった。
# 読み取り結果,人が修正した結果 ブルガリ~YG脂肪0プ,ヨーグルト プルガリアYG脂肪0Qプ,ヨーグルト フルガリアYG脂肪0プ,ヨーグルト ブルガリアYG脂肪0プ,ヨーグルト ブルガリアYG脂肪0プ。,ヨーグルト ブルガリア了YG脂肪0Uプ,ヨーグルト フルガリア了YG脂肪0プ,ヨーグルト ブルガリア了YG脂肪0プ,ヨーグルト ワルガリアYG脂肪0プ,ヨーグルト
上記の例だと漢字の「脂肪」は毎回正しく読み取れている。ただ、漢字でも正しく認識されていないことも多い。
例えば「超熟(6)」と印字されていた場合の読み取り結果の履歴一覧は以下のようになっている。熱と熟など人間から見てほぼ同じに見えるものから、弟と熟などそこまで似ていないように見えるものまである。
# 読み取り結果,人が修正した結果 記熟(6),食パン 超衣(6),食パン 超熟(6),食パン 超熱(6),食パン 超誰(6),食パン 超弟(6),食パン 超認(6),食パン
履歴を眺めているとなんとなく画数の多い漢字の方が正答率が高く、カタカナやひらがなは正答率が低い傾向に見えた(なお、ここでは示していないが半角カタカナの印字の場合、元の文字列を類推することが不可能なレベルのもっと壊滅的な結果が得られる)。
今回の対応範囲は、上で示したヨーグルトと食パンのような人間が見れば同一品目と類推できるようなレベルの読み取りであれば、自動で変換して欲しいという点においた。
やったこと
読み取り結果に完全一致する品目が履歴になくても、類似度が高い品目が履歴にあれば自動でその品目名に修正するようにした。
具体的には、履歴の品目の文字列群と今回読み取った文字列のレーベンシュタイン距離を計算し、距離が最短の品目について閾値を下回っていればその品目(の人が修正した結果)に変換するようにした。距離の閾値については、いくつか試した上でバランスを見て定めた(後述)。
※ 類似度として使用したレーベンシュタイン距離については別記事に整理した
イメージを持ちやすくするためまずはレーベンシュタイン距離を求めた結果を示す。
※ 以下、レーベンシュタイン距離は文字列の長さで正規化しているため、最大で1となる
「ブルガリアYG脂肪0プ」という文字列に対してだと、以下のようなレーベンシュタイン距離となった。ブルガリアヨーグルト関連の文字列に対して距離が小さい(=類似度が高い)一方、他の品目に対しては距離がぐっと伸びている(=類似度が低い)ことがわかる。
# 読み取り結果, 人が修正した結果, レーベンシュタイン距離 ブルガリア了YG脂肪0プ, ヨーグルト, 0.08 プルガリアYG脂肪0Qプ, ヨーグルト, 0.17 ニニガリアツアグ, 厚揚げ, 0.73 アルカリ乾電池単1形, 電池, 0.82 リがクリループ\\", ガム, 0.91
今回の目的に対し使えそうな感触を得られたので、以下のデータを用いて自動変換する距離の閾値を求めていった。
- 履歴にある品目数: 321件(人による修正結果単位で見ると141件) - テストデータの品目数: 56件
いくつか具体例を示す。
例1:読み取り結果が「シーチキン[|Newマイルド」だった場合、履歴の品目のうち最小距離となるのは「シーチキンNeeマイルド」だった。これらは人が同一品目と判断する例なので、一致すると判断し自動変換して欲しい。両者の距離は0.21だったため、閾値を0.21以上に設定していれば正しく変換できることになる。
例2:読み取り結果が「ミツカンやさしいお酢3」だった場合、履歴の品目のうち最小距離となるのは「生しいたけ」だった(両者の文字列に「しい」が共通しているため最小となったと思われる)。これらは人が別品目と判断する例なので、読み取り結果に一致する品目が履歴にないと判断して欲しい。両者の距離は0.82だったため、閾値を0.82以上に設定した場合は誤変換してしまうことになる。
このように、閾値をいくつに設定するかによって正しく変換できなかったり、誤って別の品目に変換してしまう可能性がある。
閾値を0.3から0.8の範囲で変えてみて、変換結果の割合を確認したのが下図となる。
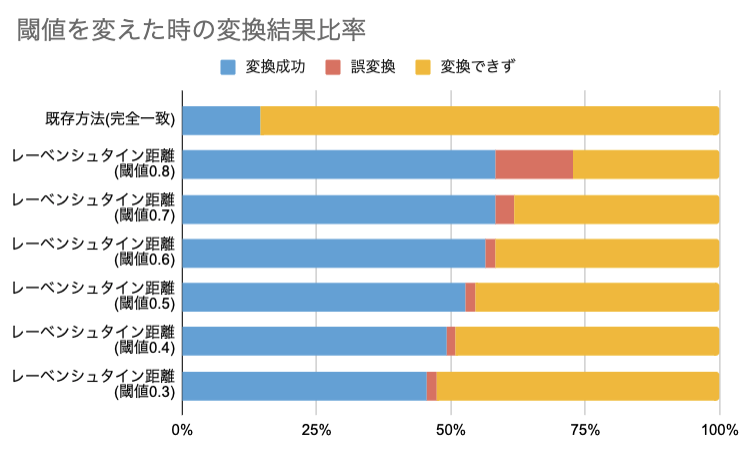
完全一致した場合のみ変換する既存の方法に比べ、レーベンシュタイン距離を用いると変換成功する確率が上がることがわかる。また、閾値を高く設定する(= 類似度が比較的低くても変換する)と変換に成功する確率が上がるが、同時に誤変換する確率も上がる。
今回は、誤変換と変換成功のバランスをみつつ、誤変換に気づかずそのまま記録するよりは変換できずに手動で修正する方が良いと考え(偽陽性を防ぐイメージ)、閾値を0.5に設定することとした。
今後
いったん上記の方法で類似度を出す方法を組み込んだので、しばらく利用して感触を確かめてみる。以下のあたりが次の課題だと現時点では考えている。
- 漢字とひらがなの表記揺れへの対応(例えば「たまねぎ」と「玉ねぎ」は距離が0とならないため、より距離が短い品目があるとそちらに誤変換されてしまう)
- 半角カタカナへの対応(上記で記載したが、半角カタカナの読み取り精度は著しく低いので、同じ品目でも読み取り結果のばらつきが大きすぎ、今回の類似度による変換はほぼ効かない)
