
これは、類似度を用いてレシートOCRの精度を上げるで文字列間の類似度を判定するために使用した、レーベンシュタイン距離について自分の理解のためにまとめた記事となる。
レーベンシュタイン距離とは
レーベンシュタイン距離は、文字列間の類似度を距離として示すもの(距離が近いほど類似していることを示す)。挿入・削除・置換の各操作を合計で何回行えばもう一方の文字列に変換できるかで距離を測る。
挿入・削除・置換はそれぞれ以下の操作を指す。
- 挿入:1文字を挿入する e.g. たこ → たいこ
- 削除:1文字を削除する e.g. たいこ → たこ
- 置換:1文字を置換する e.g. たこ → たて
これらの操作を最小の回数だけ行い、もう一方の単語に変換する。
例えば「とまと」と「たまご」なら、以下のように2回置換を行うのが一番手数が少なく変換できるのでレーベンシュタイン距離は2となる(※)
「とまと」
→ とをたに変換して「たまと」
→ とをごに変換して「たまご」
※ 用途により挿入・削除・置換それぞれの重み付けを変えることもできるが、等しい重みとしている(以下も同様)。
レーベンシュタイン距離を求めるには
以下のような2次元配列を用意して、各セルに各単語のクロスする部分文字列間のレーベンシュタイン距離を入れていく。
左上は□(空文字列)と□(空文字列)のレーベンシュタイン距離で、同じ文字列なのでレーベンシュタイン距離は0と確定する。そこから右下に向かって順次求めていくと、最後に元々求めたかった文字列間のレーベンシュタイン距離が求まる。
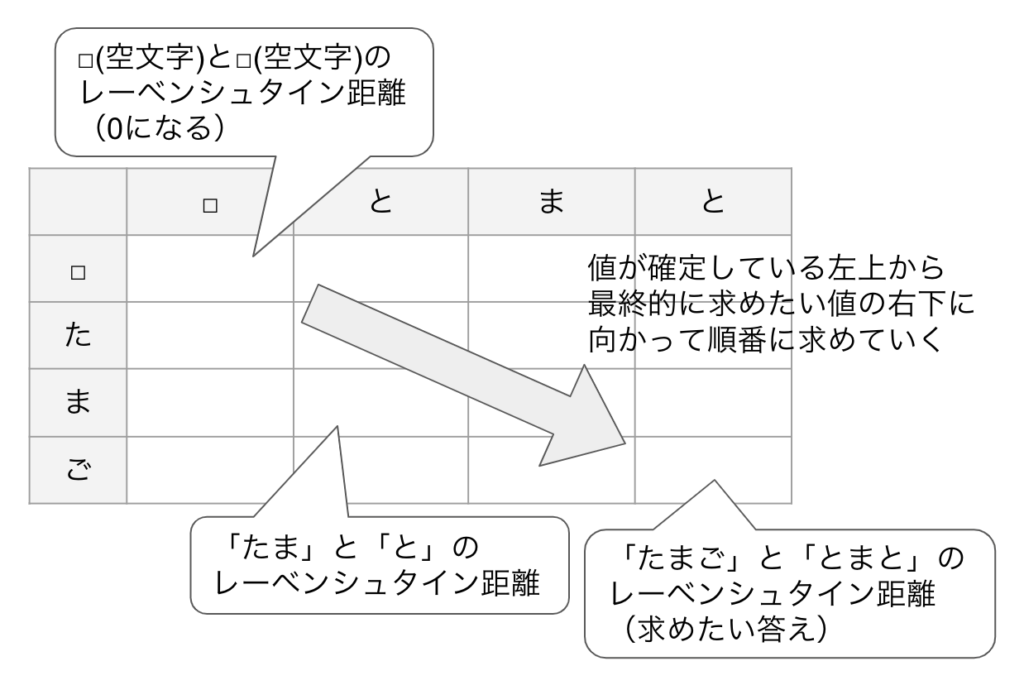
具体的な流れを見ていくと
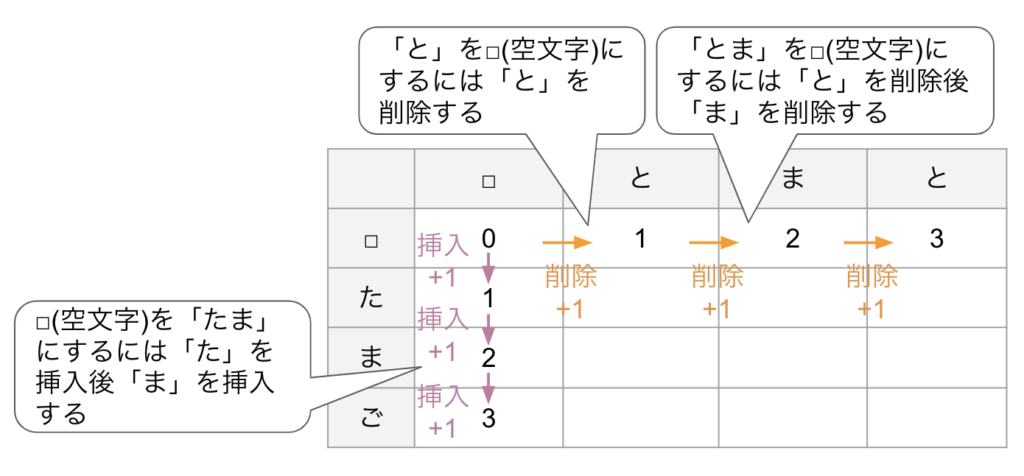
① 空文字との距離である0行目・0列目はそれぞれ削除と挿入により至るセルなので、それぞれ一つ上/左のセルの距離+1が入る
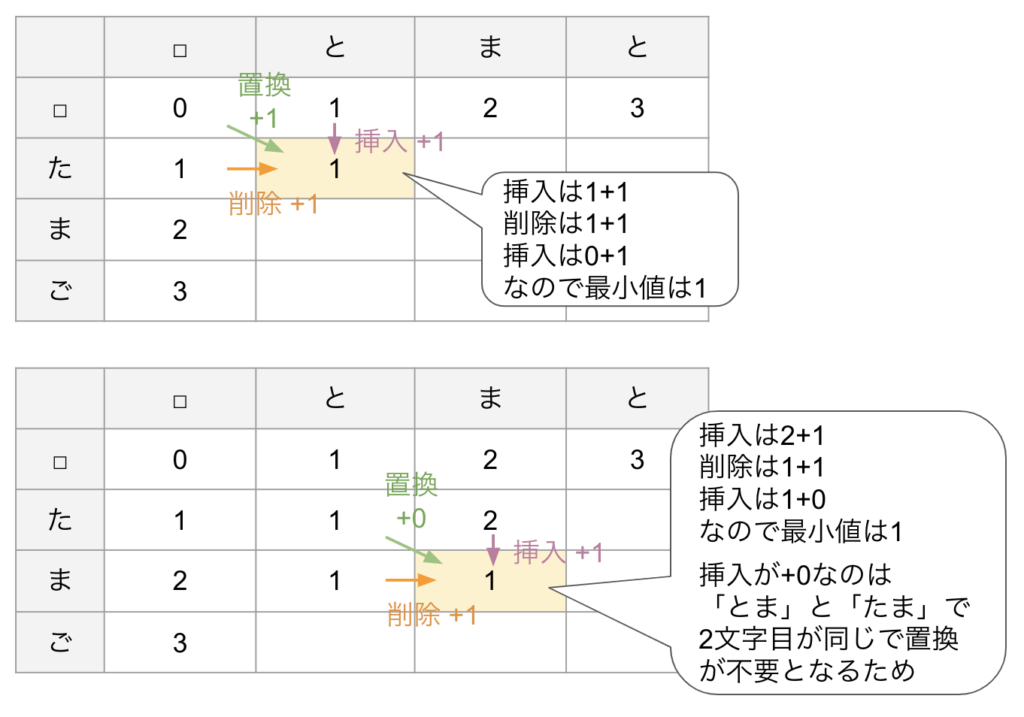
② ①以外のセルは、置換によってもたどり着けるセルのため、削除と挿入に加え置換も考える。置換については斜め上のセルの距離から+1あるいは+0となる。挿入・削除・置換のうち、一番短い距離がそのセルの値となる(なるべく短くなるような距離が求めたいため)。
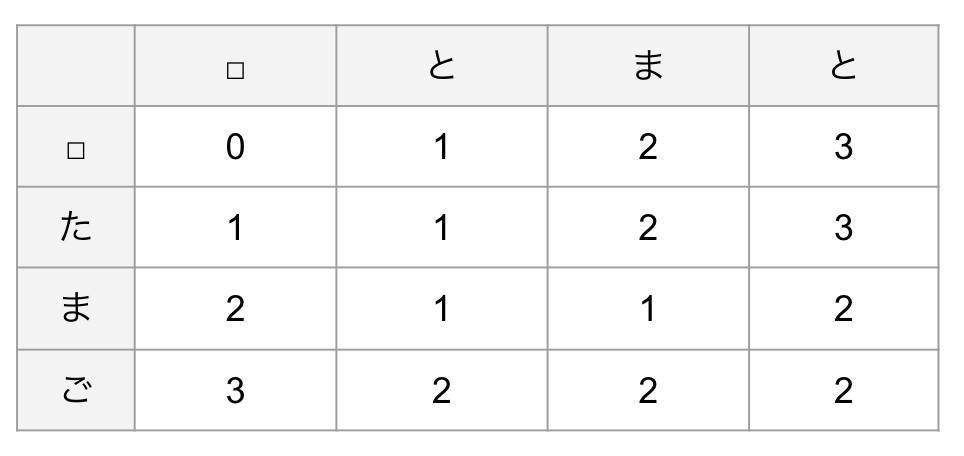
③ 最終的に右下までたどり着くと、2単語間のレーベンシュタイン距離が求まったことになる。
※ 一般に文字列が長いほど距離が長くなるため、レーベンシュタイン距離同士を比較する際に文字列の長さで割って標準化する場合もある
Pythonでレーベンシュタイン距離を求める処理を書く
上記の流れを素直にそのままPythonで書いた。
def levenshtein(word_A, word_B):
# 挿入・削除・置換のコストを定義しておく
INSERT_COST = 1
DELETE_COST = 1
SUBSTITUTE_COST = 1
# 2次元配列を用意しておく
distances = []
len_A = len(word_A)
len_B = len(word_B)
dp = [[0] * (len_B + 1) for _ in range(len_A + 1)]
# 上記①の工程
for i in range(len_A + 1):
dp[i][0] = i * INSERT_COST
for i in range(len_B + 1):
dp[0][i] = i * DELETE_COST
# 上記②の工程
for i_A in range(1, len_A + 1):
for i_B in range(1, len_B + 1):
insertion = dp[i_A - 1][i_B] + INSERT_COST
deletion = dp[i_A][i_B - 1] + DELETE_COST
substitution = (
dp[i_A - 1][i_B - 1]
if word_A[i_A - 1] == word_B[i_B - 1]
else dp[i_A - 1][i_B - 1] + SUBSTITUTE_COST
)
dp[i_A][i_B] = min(insertion, deletion, substitution)
# 上記③の工程
distance = dp[len_A][len_B] / max(len_A, len_B) # 標準化している
return distance